GoLang 初见
官方文档翻译与实践
Go编码前置知识
go以包的形式组织代码,一个包(package)代表一个文件夹下一系列源文件的集合,他们会被一起编译,被定义在同个包下的方法(functions)、类型(types)、变量(variables)、常量(constants),在该工作区下是共享可见的。
一个存储库,可以包含一个或者多个模块(modules),一个模块是一系列一起发布的相关go包(packages)的集合。一个go存储库,通常只包含一个模块(module),位于存储库的根目录。根目录下有个名为go.mod的文件声明了该模块的模块路径:模块内所有包的导入路径前缀。该模块包含其下级具有自己的go.mod文件的直属模块,不含直属模块下级包含go.mod文件的子目录。(这个存疑,感觉文档写的英语有点绕,等后面在看到合适的解释,再修改)
go工作空间,允许你使用本地依赖,类似于Monorepo模式下的工作空间,本地依赖可以作为实际依赖进行引入。
go包的导入path:go.mod文件中的首行module example.com/web-service-gin,不仅声明了包的名字,也表示了该包的下载地址应为: https://example.com/web-service-gin。
在指定module内执行go install、go install .、go install 该包的module path,会build该包为二进制可执�行文件到GOBIN目录下,如需修改/重置GOBIN环境变量配置,可通过以下命令:
# 默认为 linux等:$HOME/go/bin windows: /users/XXX/go/bin
# 修改
go env -w GOBIN=/somewhere/else/bin
# 重置
go env -u GOBIN
go install这样的命令,需要在module包中执行,否则会报错,要区别于前端的npm install;为了方便起见,go 命令接受相对于工作目录的路径,所以在module包内指定go.mod位置,执行go install、go install .、go install 该go.mod声明的module path是等效�的。
环境变量GOPATH指定了go程序的工作区位置,GOBIN环境变量也可配置为:%GOPATH%/bin
添加go工作区位置到系统环境变量,则工作区内bin目录的二进制可执行文件即可快速在任何位置执行
# Windows users should consult /wiki/SettingGOPATH 其实就是将 /users/xxx/go目录添加到环境变量
# for setting %PATH%. -- linux等
export PATH=$PATH:$(dirname $(go list -f '{{.Target}}' .))
hello
# Hello, world.
包名(module path)的命名规范,应可以直接匹配为:HTTPS URL,这样更有利于��别人或者自己引用,也有助于代理服务收录。
如何引用本地包呢,可以创建一个本地包的形式进行演示:
在hello目录新建morestrings目录,该目录下新建revers.go,并键入如下代码:
// 引用官网示例
// Package morestrings implements additional functions to manipulate UTF-8 encoded strings,
// beyond what is provided in the standard "strings" package.
package morestrings
// ReverseRunes returns its argument string reversed rune-wise left to right.
func ReverseRunes(s string) string {
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r)
}
由于我们编写的function使用了upper-case形式命名,所以他是一个被导出的方法,可以被引入他的其他包使用。
接下来可以在当前目录执行go build,这不会产生输出文件。相反,它会将编译后的包保存在本地构建缓存中。--这样我们就可以在其他包进行直接引用
然后我��们可以在hello目录,新建主入口文件hello.go,并编写代码如下:
package main
import (
"fmt"
"example/user/hello/morestrings"
)
func main() {
fmt.Println(morestrings.ReverseRunes("!oG ,olleH"))
}
随后执行go install,更新可执行二进制执行文件,完成后执行hello命令
hello
# Hello, Go!
引入远程的包,则需要引入后执行go mod tidy进行远程包下载(已下载过的包就不会再次下载了),此命令还会删除没用到的包。
go mod tidy下载的包会被下载到GOPATH目录下的pkg/mod子目录中,被下载到这里的module,会共享到其他modules(如果引入的版本号一致);所以此目录中的文件都是只读的。如需移除所有下载过的modules,则需要执行:
go clean -modcache
Go 已经内部集成了一个由 go test 命令和测试包组成的轻量级测试框架。如需编写测试代码,可以参考如下官方提供代码:
package morestrings
import "testing"
func TestReverseRunes(t *testing.T) {
cases := []struct {
in, want string
}{
{"Hello, world", "dlrow ,olleH"},
{"Hello, 世界", "界世 ,olleH"},
{"", ""},
}
for _, c := range cases {
got := ReverseRunes(c.in)
if got != c.want {
t.Errorf("ReverseRunes(%q) == %q, want %q", c.in, got, c.want)
}
}
}
然后在当前测试模块目录,执行以下命令:
cd /hello/morestrings
go test
# PASS
# ok example/user/hello/morestrings 0.165s
清楚以上内容后,对go的开发模式就有了基本来了解,接下来进一步深入go的基础开发过程,最后进阶web框架
Golang官网入门文档
1. Go程序包获取/安装/卸载
- 最简单的方法就是下载指定平台的二进制安装包进行安装
https://go.dev/doc/install - 其次是源码编译安装 这个官网有详细文档,新学者不建议,真正熟悉golang后,如需开发高效基于go核心的包,再进行此方面研读
- 多版本管理,需要gitshell支撑,执行如下命令
go install golang.org/dl/go1.10.7@latest
go1.10.7 download
go1.10.7 version
## go version go1.10.7 linux/amd64
go1.10.7 env GOROOT
## 可以查看此版本的环境变量目录
## 要卸载指定版本的go, 只需要通过此版本的环境变量找到指定目录的二进制包进行直接删除 更多平台卸载方式,可以参考官方
2. 开始使用go进行代码编写
- 初始化工作空间
在常用的工作目录新建文件夹,在此文件夹位置打开cmd/shell/bash等,执行如下脚本
mkdir hello
cd hello
# go mod 可以进行golang项目工作空间初始化工作
go mod init example/hello
# go: creating new go.mod: module example/hello
# go: to add module requirements and sums:
# go mod tidy
执行后会发现,目录中生成了go.mod文件,
随后在当前目录新建hello.go文件,编写如下入门代码:
package main
import ("fmt")
func main() {
fmt.Println("Hello World!")
}
保存后,终端执行go run .,终端打印Hello World!,标志着完成了go的第一个程序运行
注意点1:引入go包的方式,
import 'fmt'、import ('a/exmaple/mod' \n b/example/mod)
注意点2:main 函数一个包里只会有一个主入口函数
3. 调用外部包中的代码(导入模块、或内部模块)
go生态包检索:pkg.go.dev
当开发过程中,需要使用其他已开发好的其他模块,我们需要这样做:
- 在上述生态包检索页面搜索需要的包
- 通过import关键字声明引入
- 执行
go mod tidy,等待模块下载完毕,即可在代码中使用
代码示例:
package main
import (
"fmt"
"rsc.io/quote/v4"
)
func main() {
fmt.Println("Hello world!\n")
fmt.Println(quote.Go())
}
go mod tidy: 下载/关联/删除 当前目录下的依赖模块 类似
npm install;国内执行go mod tidy一般会下载失败,这时候我们修改默认代理环境变量,需要找到go的安装目录中的go.env文件进行修改,修改如下:
# GOPROXY=https://proxy.golang.org,direct
GOPROXY=https://goproxy.cn,direct ## 使用七牛云代理
# 如果失效,自行百度
或者执行以下脚本设置 下述方式优先级大于go.env文件配置,执行下面的脚本后,go.env文件的�下载代理可以不用修改
go env -w GO111MODULE=on
go env -w GOPROXY=https://goproxy.cn,direct
# windows 环境亦可通过PowerShell设置环境变量,就不用执行上述脚本了,
$env:GO111MODULE = "on"
$env:GOPROXY = "https://goproxy.cn"
完成上述的编码及配置,并下载完毕后,执行go mod tidy,等待下载/或者关联完成后,执行go run .,即可看到打印出有关通信的语录
4. 创建本地Module
Go code is grouped into packages, and packages are grouped into modules. 您的模块(go.mod)指定运行代码所需的依赖项(first require),还包括 Go 版本(go 1.24.0)和它所需的其他模块集(second require)。
- 进入工作目录
cd yourworkspaceforgo
- 创建Go 模块代码目录
mkdir greetings
- 使用
go mod init xxx,初始化模块,类似于npm init -y xxx
go mod init example.com/greetings
# go: creating new go.mod: module example.com/greetings
go mod init命令创建一个go.mod文件来跟踪代码的依赖关系,该文件中目前只包含模块名和当前模块支持的go版本号的相关声明; 但是当你添加依赖项时,go.mod文件将列出你的代码所依赖的版本。这可以保持构建的可重复性,并让你直接控制要使用的模块版本。
- 在此目录中创建
greetings.go文件,然后输入如下代码:
package greetings
import "fmt"
// Hello returns a greeting for the named person.
func Hello(name string) string {
// Return a greeting that embeds the name in a message.
message := fmt.Sprintf("Hi, %v. Welcome!", name)
return message
}
在Go中,名称以大写字母开头的函数可以被不在同一包中的函数调用。 在 Go 中,:= 运算符是一种在一行中声明和初始化变量的快捷方式(Go 使用右侧的值来确定变量的类型)。 从长远来看,您可能会将其写成:
var message string
message = fmt.Printf("Hi, %v. Welcome!", name)
以上内容,创建了第一个向外暴露函数的module,接下来我们可以在其他模块引入我们创建的module。
4.1 在go代码中使用其他模块的代码
新建模块目录 hello,初始化后,引入之前创建的module
cd ..
mkdir hello
cd hello
go mod init github.com/coderofrat/hello
新建hello.go,键入如下代码:
package main
import (
"fmt"
"rsc.io/quote/v4"
"example.com/greetings"
)
func main() {
fmt.Println("Hello world!")
fmt.Println(quote.Go())
fmt.Println(greetings.Hello("CoderOfRat"))
}
此时执行go mod tidy,将会提示找不到example.com/greetings模块:
由于引入的
example.com/greetings包尚未发布,因此为了本地适用此模块,我们需要进行路径指定,让依赖模块可以索引到本地模块。 如果要使用的包,尚未发布,比如是自己本地的module,执行go mod edit -replaace example.com/greetings=../greetings,可以告诉go tools针对此module需要重定向索引位置。该命令指定了应将 example.com/greetings 替换为 ../greetings,以便定位依赖项。
go mod edit -replace example.com/greetings=../greetings
运行该命令后,hello目录中的go.mod文件应包含一个replace指令:
模块路径后面的数字是伪版本号——用来代替语义版本号所生成的数字
module github.com/coderofrat/hello
go 1.24.0
require (
example.com/greetings v0.0.0-00010101000000-000000000000
rsc.io/quote/v4 v4.0.1
)
require (
golang.org/x/text v0.22.0 // indirect
rsc.io/sampler v1.3.0 // indirect
)
replace example.com/greetings => ../greetings
从 hello 目录中的命令提示符中,运行 go mod tidy 命令来同步 example.com/hello 模块的依赖项,添加代码所需但尚未在模块中跟踪的依赖项。
$ go mod tidy
go: found example.com/greetings in example.com/greetings v0.0.0-00010101000000-000000000000
执行后,go.mod 文件中的内容如下:
module example.com/hello
go 1.24.0
replace example.com/greetings => ../greetings
require example.com/greetings v0.0.0-00010101000000-000000000000
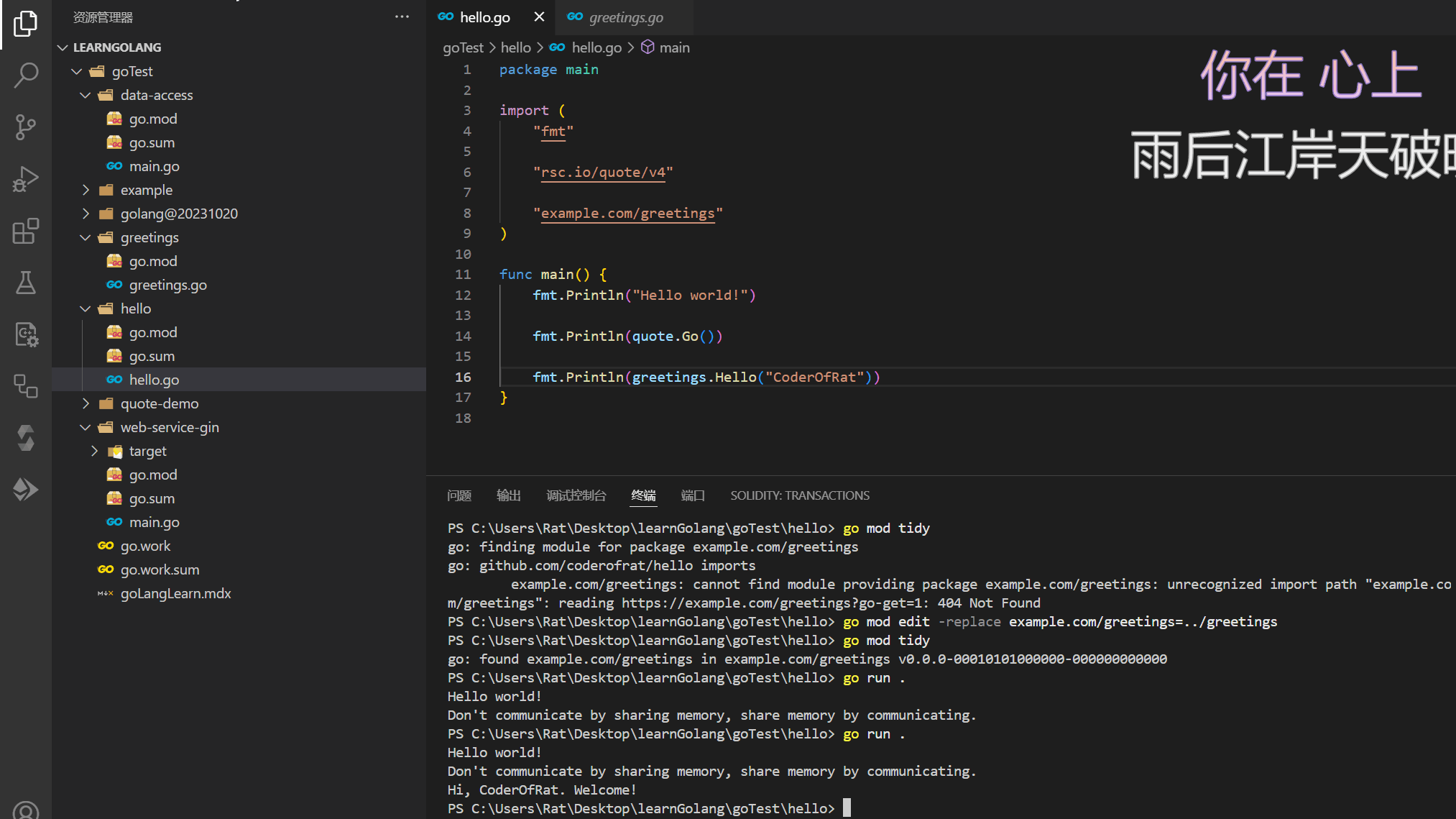
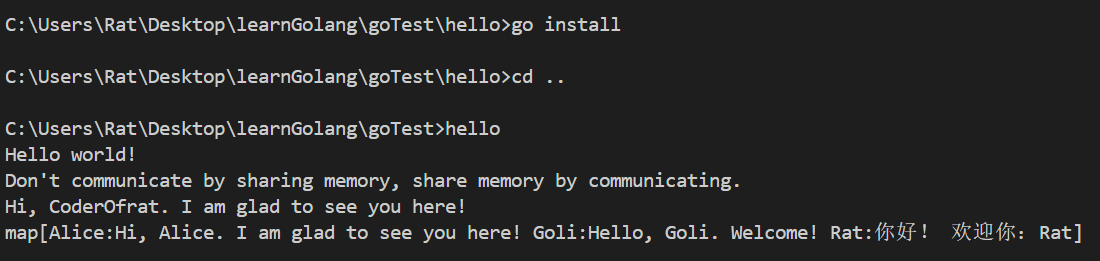
随后执行go run .,输出如下:
go run .
# Hello world!
# Don't communicate by sharing memory, share memory by communicating.
# Hi, CoderOfRat. Welcome!
至此,已经完成了两个可运行模块的编写/运行,接下来我们来给代码添加一些错误处理逻辑
4.2 错误处理逻辑
代码的错误处理逻辑,是让go代码保持健壮的基本要素,我们给之前的greetings模块添加错误处理的相关代码:
package greetings
import (
"errors"
"fmt"
)
// Hello returns a greeting for the named person.
func Hello(name string) (string, error) {
// 如果names输入为空字符串,则返回空字符串,抛出异常信息(异常信息开头首字母不允许大写)
if name == "" {
return name, errors.New("empty name provided")
}
// Return a greeting that embeds the name in a message.
message := fmt.Sprintf("Hi, %v. Welcome!", name)
// 在成功返回时添加 nil(表示没有错误)作为第二个值。这样,调用者就可以看到函数成功了。
return message, nil
}
go 代码是静态类型编译型语言,因此错误的程序输入不会编译成功,所以异常处理一般不考虑此方面。
然后我们在使用更新后的greetings包的时候,就需要添加对应的异常捕获代码:
package main
import (
"fmt"
"log"
"rsc.io/quote/v4"
"example.com/greetings"
)
func main() {
// Set properties of the predefined Logger, including
// the log entry prefix and a flag to disable printing
// the time, source file, and line number.
// 配置日志包以在其日志消息的开头打印命令名称(“greetings:”),不带时间戳或源文件信息。
log.SetPrefix("greetings:")
log.SetFlags(0)
fmt.Println("Hello world!")
fmt.Println(quote.Go())
// fmt.Println(greetings.Hello("CoderOfRat"))
message, error := greetings.Hello("CoderOfRat")
if error != nil {
// 此打印会终止程序向下运行 Fatal is equivalent to [Print] followed by a call to os.Exit(1).
log.Fatal(error)
}
// 没有错误,打印message返回信息
fmt.Println(message)
}
go run .
# Hello world!
# Don't communicate by sharing memory, share memory by communicating.
# Hi, CoderOfRat. Welcome!
接下来,我们将greetings.Hello()方法内参数传递空字符串,再次执行:
message, error := greetings.Hello("")
go run .
# Hello world!
# Don't communicate by sharing memory, share memory by communicating.
# greetings:empty name provided
# exit status 1
此时执行到此方法时,后续代码对异常情况进行了打印并终止当前程序的处理。
完成该小结,我们错略了解了简单的错误处理方式,接下来我们要通过切片(slice)完善上述greetings模块, 使之可以返回一个随机的greeting字串
4.3 利用切片(slice),实现随机打印欢迎语
切片类似于数组,不同之处在于其大小会随着您添加和删除项目而动态变化。切片是 Go 中最有用的类型之一。
进一步修改greetings/greetings.go中的代码:
package greetings
import (
"errors"
"fmt"
"math/rand"
)
// Hello returns a greeting for the named person.
func Hello(name string) (string, error) {
// 如果names输入为空字符串,则返回空字符串,抛出异常信息(异常信息开头首字母不允许大写)
if name == "" {
return name, errors.New("empty name provided")
}
// Return a greeting that embeds the name in a message.
message := fmt.Sprintf(getRandomGreetingsFormat(), name)
return message, nil
}
// go中的func 不支持嵌套写法
func getRandomGreetingsFormat() string {
// []string 省略了长度定义,代表是可变长度的切片
greetingsArr := []string{
"Hello, %v. Welcome!",
"你好! 欢迎你:%v",
"Hi, %v. I am glad to see you here!",
}
return greetingsArr[rand.Intn(len(greetingsArr))]
}
修改hello.go,文件中的message赋值行
message, error := greetings.Hello("CoderOfrat")
在hello目录,多次执行go run .,得到如下结果:
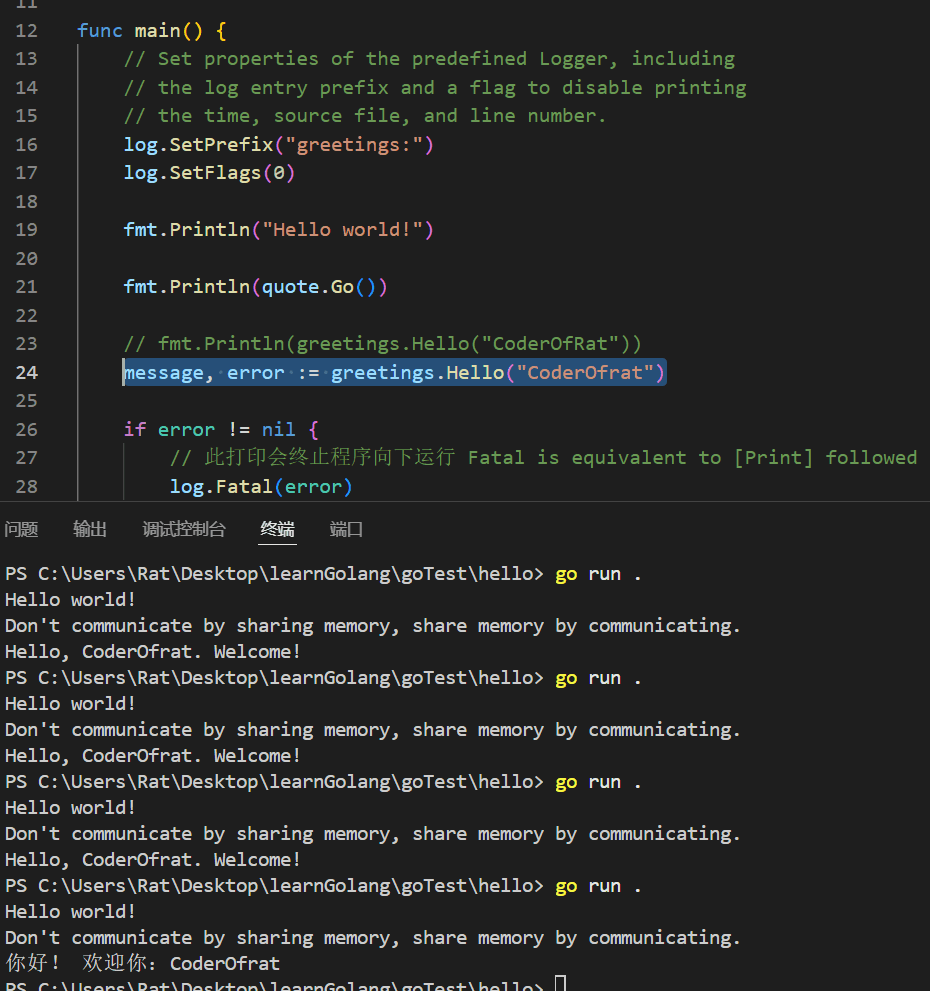
由于打印是随机的,所以结果会有所不同。
完成上述内容,初步了解了切片的用法,以及如何配合math/rand模块提供的随机取数方法,完成随机输出的逻辑,
接下来,将进一步利用切片,完成针对多人打招呼的功能,let go on ~
4.4 多人打招呼程序
为了开发流程的规范性,一般我们如果稳定提供了某个功能(func),并且发布被别人使用了, 那么我们始终在一个func上进行实现和扩展,将给使用者带来灾难性的问题,因此,如果新开发的功能不是渐进式补充的, 而是新的出入参、核心逻辑等,那就要考虑新建方法了(可以复用同包的逻辑)。
greetings.go
package greetings
import (
"errors"
"fmt"
"log"
"math/rand"
)
// Hello returns a greeting for the named person.
func Hello(name string) (string, error) {
// 如果names输入为空字符串,则返回空字符串,抛出异常信息(异常信息开头首字母不允许大写)
if name == "" {
return name, errors.New("empty name provided")
}
// Return a greeting that embeds the name in a message.
message := fmt.Sprintf(getRandomGreetingsFormat(), name)
return message, nil
}
func getRandomGreetingsFormat() string {
greetingsArr := []string{
"Hello, %v. Welcome!",
"你好! 欢迎你:%v",
"Hi, %v. I am glad to see you here!",
}
return greetingsArr[rand.Intn(len(greetingsArr))]
}
func Greetings(names []string) (map[string]string, error) {
messages := make(map[string]string, len(names))
if len(names) == 0 {
return messages, errors.New("none name provide")
}
// 循环遍历函数收到的名称,检查每个名称是否具有非空值,然后将消息与每个名称关联起来。
// 在此 for 循环中,range 返回两个值:循环中当前项的索引和项值的副本
// 您不需要索引,因此可以使用 Go 空白标识符(下划线)来忽略它。
for _, name := range names {
message, err := Hello(name)
if err != nil {
log.Fatal(err)
}
messages[name] = message
}
return messages, nil
}
::: note[文件] hello.go :::
package main
import (
"fmt"
"log"
"rsc.io/quote/v4"
"example.com/greetings"
)
func main() {
// Set properties of the predefined Logger, including
// the log entry prefix and a flag to disable printing
// the time, source file, and line number.
log.SetPrefix("greetings:")
log.SetFlags(0)
fmt.Println("Hello world!")
fmt.Println(quote.Go())
// fmt.Println(greetings.Hello("CoderOfRat"))
message, error := greetings.Hello("CoderOfrat")
if error != nil {
// 此打印会终止程序向下运行 Fatal is equivalent to [Print] followed by a call to os.Exit(1).
log.Fatal(error)
}
// 没有错误,打印message返回信息
fmt.Println(message)
messages, err := greetings.Greetings([]string{
"Rat",
"Alice",
"Goli",
})
if err != nil {
log.Fatalln(err)
}
fmt.Println(messages)
}
上述代码,我们更改了入参和返参,通过切片传入一系列人名,然后,使用for关键字,循环使用传入的参数调用之前定义的Hello函数,并将返回结果接收到使用make关键字创建的string Map(map[string]string)中。最终返回以人名为键、以欢迎语为值的map。在 Go 中,您可以使用以下语法初始化映射:make(map[key-type]value-type)。
本主题介绍了用于表示名称/值对的映射。还介绍了通过为模块中的新功能或更改的功能实现新函数来保持向后兼容性的想法。了解更多go的向后兼容开发模式。
接下来,我们使用内置的 Go 功能为此模块代码创建单元测试。
4.5 添加单元测试
Go 内置了对单元测试的支持,可以更轻松地进行测试。具体来说,使用命名约定、Go 的
testing package和go test命令,可以快速编写和执行测试。
- 在greetings目录创建
greetings_test.go,文件名以_test.go结尾,告诉了go test命令该文件包含测试函数。
在greetings_test.go文件中输入以下代码:
package greetings
import (
"testing"
"regexp"
)
// TestHelloName calls greetings.Hello with a name, checking
// for a valid return value.
func TestHelloName(t *testing.T) {
name := "Gladys"
want := regexp.MustCompile(`\b`+name+`\b`)
msg, err := Hello("Gladys")
if !want.MatchString(msg) || err != nil {
t.Errorf(`Hello("Gladys") = %q, %v, want match for %#q, nil`, msg, err, want)
}
}
// TestHelloEmpty calls greetings.Hello with an empty string,
// checking for an error.
func TestHelloEmpty(t *testing.T) {
msg, err := Hello("")
if msg != "" || err == nil {
t.Errorf(`Hello("") = %q, %v, want "", error`, msg, err)
}
}
然后执行go test,可以发现执行成功,终端打印如下:
PASS
ok example.com/greetings 0.521s
go test 命令执行测试文件(名称以 _test.go 结尾)中的测试函数(名称以 Test 开头)。可以添加 -v 标志以获取列出所有测试及其结果的详细输出。
go test -v
// === RUN TestHelloName
// --- PASS: TestHelloName (0.00s)
// === RUN TestHelloEmpty
// --- PASS: TestHelloEmpty (0.00s)
// PASS
// ok example.com/greetings 0.063s
接下来,我们修改greetings模块中的Hello方法,使返回内容,不包含测试内容(!want.MatchString(msg)),即不符合条件。
// Hello returns a greeting for the named person.
func Hello(name string) (string, error) {
// 如果names输入为空字符串,则返回空字符串,抛出异常信息(异常信息开头首字母不允许大写)
if name == "" {
return name, errors.New("empty name provided")
}
// Return a greeting that embeds the name in a message.
// 注释了此行
// message := fmt.Sprintf(getRandomGreetingsFormat(), name)
// 新加上此行
message := fmt.Sprint(getRandomGreetingsFormat())
return message, nil
}
然后我们可以再次执行go test -v,可以发现测试内容是否包含的TestHelloName单元测试不通过,但是测试空返回的测试单元可以通过。
go test -v
# === RUN TestHelloName
# greetings_test.go:15: Hello("Gladys") = "你好! 欢迎你:%v", <nil>, want match for `\bGladys\b`, nil
# --- FAIL: TestHelloName (0.00s)
# === RUN TestHelloEmpty
# --- PASS: TestHelloEmpty (0.00s)
# FAIL
# exit status 1
# FAIL example.com/greetings 0.940s
添加良好的单元测试代码,有助于提升预期实现,使我们的模块更健壮可用,接下来可以编译生成可运行程序啦~
4.6 编译安装go代码
在最后一个主题中,您将学习几个新的 go 命令。虽然go run 命令是您在频繁更改时编译和运行程序的有用快捷方式,但它不会生成二进制可执行文件。
接下来我们使用下列命令,进行go代码的编译及安装。
go build命令会编译软件包及其依赖项,但不会安装结果。go install命令会编译并安装软件包。
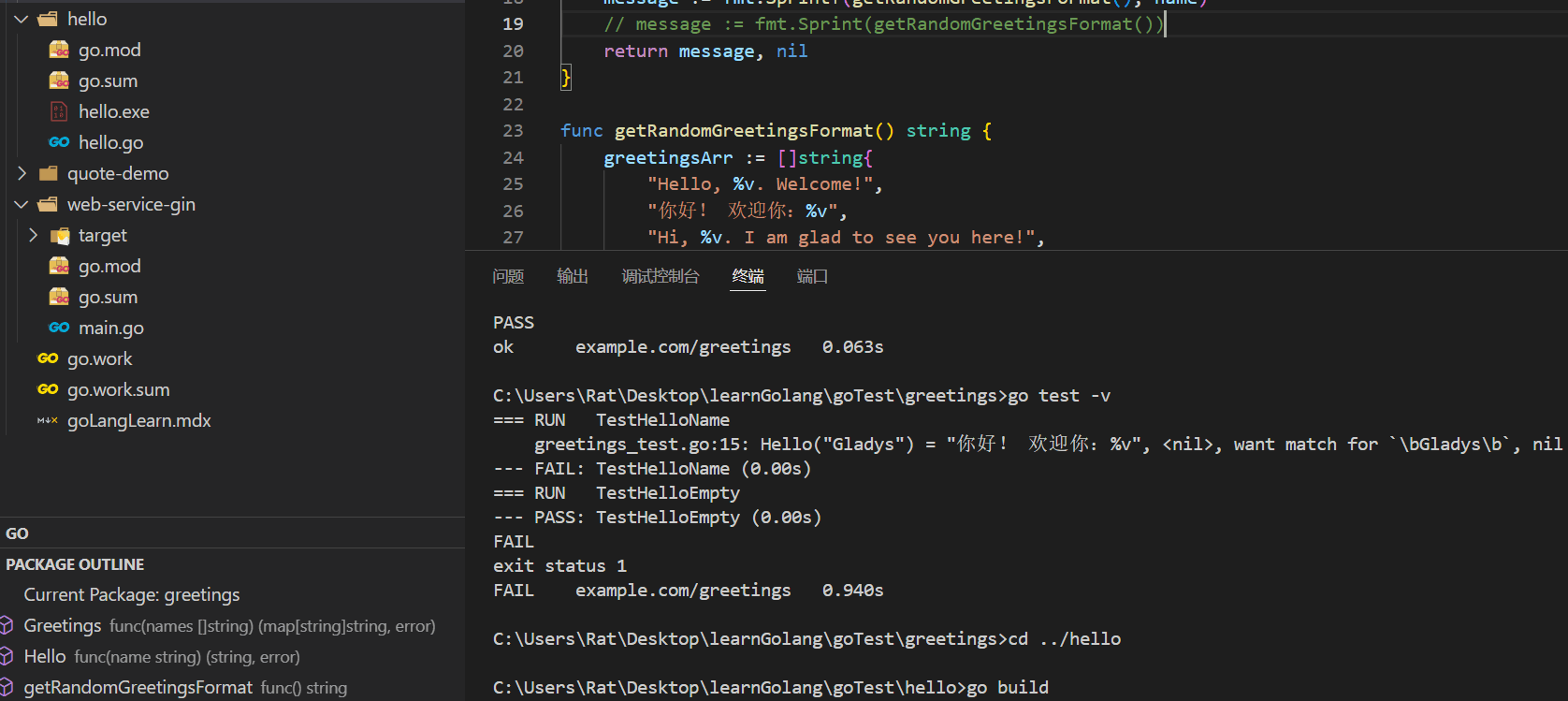
- 恢复之前在测试单元更改的内容,保存后,在 hello 目录中的命令行中,运行 go build 命令将代码编译为可执行文件。
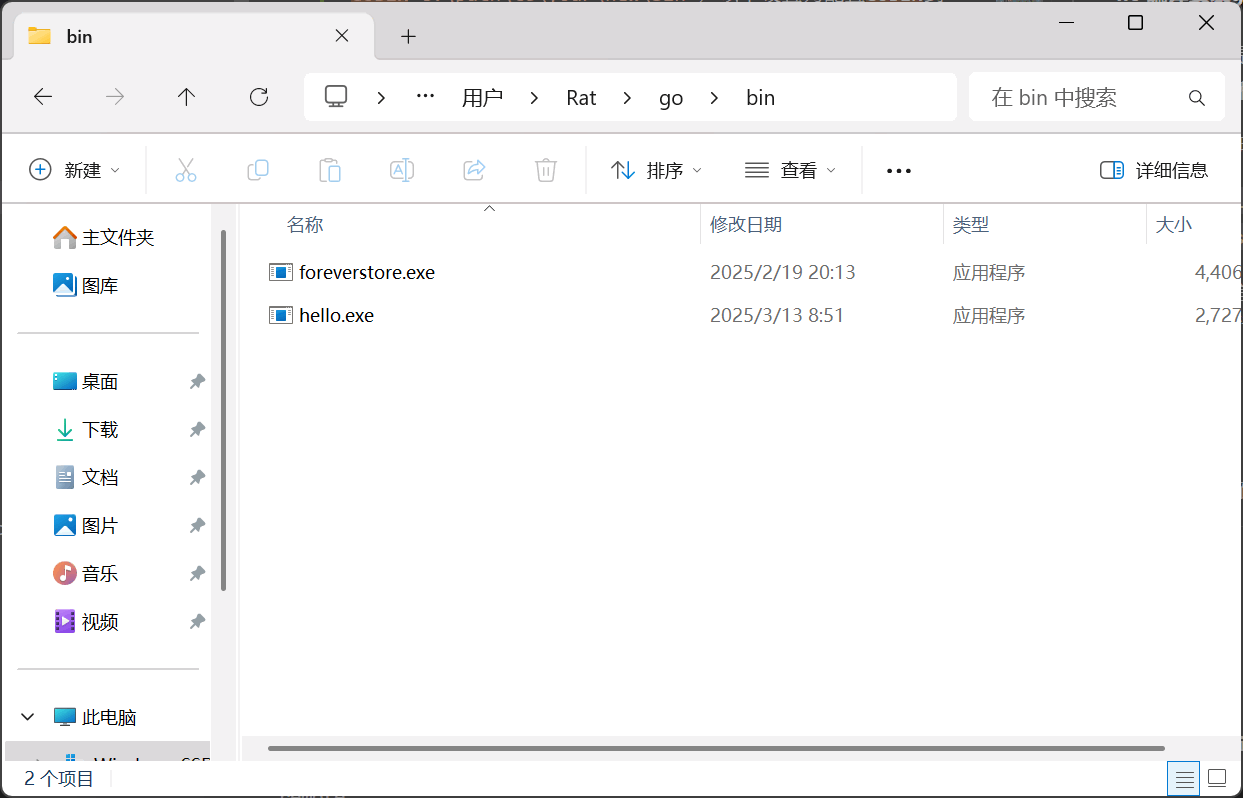
go build
执行后,可以在同级目录生成hello.exe可执行文件:
然后在命令行继续键入hello或者hello.exe,即可看到程序输出:
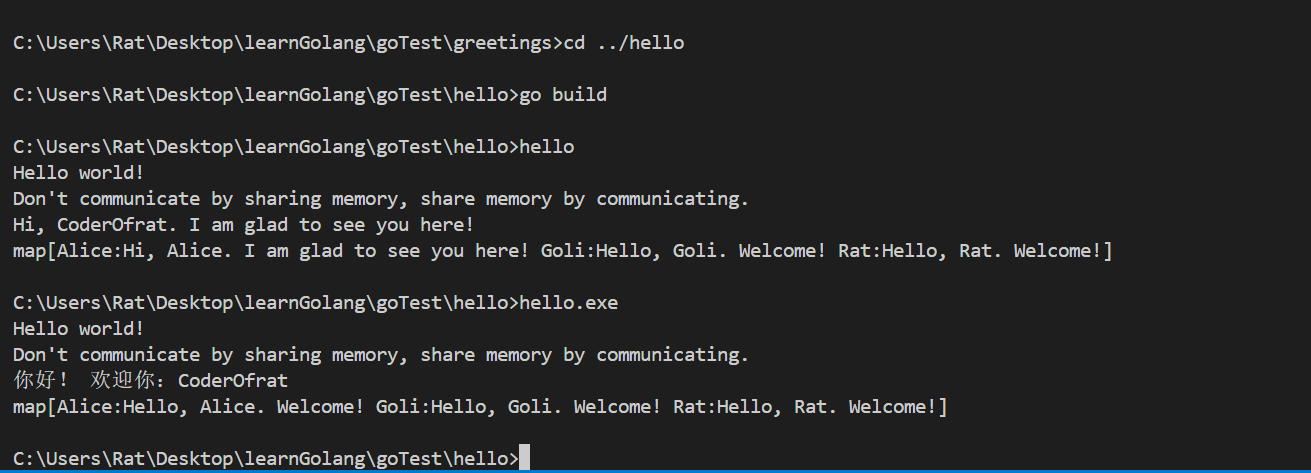
您已将应用程序编译为可执行文件,因此可以运行它。但目前要运行它,您的命令需要位于可执行文件的目录中,或者指定可执行文件的路径。接下来,我们可以执行go install对此go程序进行安装,以至于可以随处运行此程序。首先我们需要先找到 Go 安装路径,go install 命令将在此安装当前包。 可以通过运行 go list 命令来找到安装路径,如下例所示:
go list -f '{{.Target}}'
# 'C:\Users\Rat\go\bin\hello.exe'
这代表go install会将hello程序安装到C:\Users\Rat\go\bin目录下,也就是之前我们说的 GOBIN=%GOPATH%/bin,如需修改,可执行命令go env -w GOBIN=C:\path\to\your\new\bin,以下设置为配置GOBIN到path环境变量中。
export PATH=$PATH:/path/to/your/install/directory # linux
set PATH=%PATH%;C:\path\to\your\install\directory # win
完成以上配置后,执行go install之后,即可在系统任意目录进行执行 hello命令,运行该程序。
至此,已经完成了对go语言的基本了解,接下来,我们需要进一步了解实际开发过程中的常见问题。
5. 多模块工作区(multi-module workspaces)
使用多模块工作区,指明了我们在多个模块中编写代码,并go命令轻松地在这些模块中构建和运行代码。
5.1 创建多模块工作目录
执行如下命令,进行初始化项目
cd 你想要创建工作目录的文件夹(dir where you want to create multi-module)
mkdir workspace
cd workspace
mkdir hello
go mod init github.com/CoderOfRat/hello
# 获取远程已发布的模块 本质上go mod tidy 包含了此操作,只是一个是前置直接先下载依赖再引用,一个是项目中引用,再分析下载
go get golang.org/x/example/hello/reverse
再hello目录创建hello.go文件,并键入如下内容:
package main
import (
"fmt"
"golang.org/x/example/hello/reverse"
)
func main() {
fmt.Println(reverse.String("Hello"))
}
执行结果如下:
go run .
# olleH
接下来,我们将创建一个 go.work 文件来指定带有模块的工作区。
- 初始化工作区(initialize the workspace)
cd ..
go work init ./hello
go work init命令告诉 go 为包含在./hello目录中的模块创建一个工作区(共享)。
此时在workspace目录生成了go.work文件,go.work 文件的语法与 go.mod 类似,内容如下:
go 1.24.0
use ./hello
go 指令告诉 Go 该文件应使用哪个版本的 Go 进行解释。它类似于
go.mod文件中的go指令。use指令告诉 Go,在进行构建时,hello目录中的模块应该是主模块。因此,在工作区的任何子目录中,该模块都将处于生效(可用)状态。类似于pnpm等工作区概念。
此时,我们在workspace目录执行go run ./hello:
go run ./hello
# olleH
依然可以完成程序运行
Go 命令将位于工作区中的所有模块都作为主模块。这样,我们就可以引用模块中的包,甚至在模块外部也可以。在模块或工作区外运行 go run 命令会�导致错误,因为 go 命令不知道要使用哪个模块,在工作区内运行go run命令,需要指定模块目录。
- 接下来,我们拷贝一份
golang.org/x/example远程包,并向/hello/reverse模块添加一个新方法,使之支持数值反转:
# 在workspace目录执行
git clone https://go.googlesource.com/example
# 克隆成功后执行
go work use ./example/hello
此时,我们克隆的包也被添加到了工作区,工作区文件内容此时为:
go 1.18
use (
./hello
./example/hello
)
- 在
hello/reverse目录下新建文件int.go,代码如下:
package reverse
import "strconv"
// Int returns the decimal reversal of the integer i.
func Int(i int) int {
i, _ = strconv.Atoi(String(strconv.Itoa(i)))
return i
}
- 修改
hello.go中的代码如下:
package main
import (
"fmt"
"golang.org/x/example/hello/reverse"
)
func main() {
fmt.Println(reverse.String("Hello"), reverse.Int(23456))
}
随后运行go run .,如果在workspace目录,可以执行go run ./hello,结果如下:
go run ./hello
# olleH 65432
Go命令在go.work文件指定的hello目录中找到命令行中指定的github.com/CoderOfRat/hello模块,同样使用go.work文件解析golang.org/x/example/hello/reverse的导入。
因此,可以使用 go.work 来代替
replace指令(此指令之前在4.1章节提到过)来跨多个模块工作。该例子中,由于两个模块位于同一个工作区,因此可以轻松地在一个模块中进行更改并在另一个模块中使用它。
未来,我们可以发布我们的包,其他项目引用,只需要通过go get获取,作为内部依赖使用,这样go命令就可以正常解析工作区以外的模块了。
除了我们刚才看到的 go work init 之外,go 命令还有几个用于处理工作区的子命令:
- go work use [-r] [dir] 如果存在,则向 dir 的 go.work 文件添加 use 指令,如果参数目录不存在,则删除 use 目录。-r 标志递归检查 dir 的子目录。
- go work edit 编辑 go.work 文件,类似 go mod edit
- go work sync 将工作区构建列表中的依赖项同步到每个工作区模块中。
接下来,我们将学习使用Gin框架开发几个Restful API
6. 使用Go + Gin框架,实现Restful API
gin web framework -- Go语言最快的全功能Web框架。晶莹剔透。
接下来,使用gin框架,完成订单新增、查询功能
6.1 设计API端点
在计算机领域,Endpoints通常被称为“端点”或“终端点”。
定义和功能
Endpoints是网络或系统中的一个特定位置或节点,可以是网络通信的起点或终点。它们通过唯一的标识符(如URL、IP地址或其他协议标识)来区分和识别。Endpoints在数据传输和通信中起着关键作用,负责接收和�发送数据,并通过不同的协议和通信方式与其他设备或系统进行交互。此外,Endpoints还用于实现访问控制和权限管理,确保系统的安全性。
应用场景
Endpoints广泛应用于各个领域和行业中,包括:
- 网络通信:在网络设备和节点中,Endpoints负责接收、转发和发送数据包,实现网络通信功能。
- Web服务和API:Endpoints以特定的URL形式提供服务,开发者通过访问这些Endpoints来获取服务或执行操作。
- 微服务架构:在微服务架构中,每个微服务都作为一个独立的Endpoint,提供特定的功能和服务。
具体实例
在Spring Boot框架中,Endpoints是应用程序提供的一种功能或服务,可以通过网络访问。Spring Boot提供了多种内置的Endpoints,如/health、/info、/metrics等,用于监控和管理应用程序的健康状况、性能指标和环境变量等信息。这些内置Endpoints可以通过配置文件进行自定义和扩展,开发人员还可以创建自定义Endpoints以提供更多的功能和服务。
好的端点设计,更易于使用者理解,本次示例包含两个端点:
-
/albums
- GET 获取 albums 列表信息,并以JSON格式响应
- POST 以请求的JSON入参,新增一个 albums
-
/albums:id
- GET 获取指定id的 album,并响应返回该 album 的JSON
6.2 初始化项目
mkdir web-service-gin
cd web-service-gin
go mod init github.com/coderofrat/web-service-gin
6.3 创建数据结构
在项目目录新建main.go文件,键入如下代码:
package main
// 定义 album 结构,用于在内存存储 album 数据
// album represents data about a record album.
type album struct {
ID string `json:"id"`
Title string `json:"title"`
Artist string `json:"artist"`
Price float64 `json:"price"`
}
// 结构标记(例如 `json:"artist"`)指定在将结构的内容序列化为 JSON 时字段的名称应为什么。
// 如果没有这些标记,JSON 将使用结构的大写字段名称 - 这种样式在 JSON 中并不常见。(因此这很必要)
// albums slice to seed record album data.
var albums = []album{
{ID: "1", Title: "Blue Train", Artist: "John Coltrane", Price: 56.99},
{ID: "2", Title: "Jeru", Artist: "Gerry Mulligan", Price: 17.99},
{ID: "3", Title: "Sarah Vaughan and Clifford Brown", Artist: "Sarah Vaughan", Price: 39.99},
}
6.4 端点代码实现
6.4.1 编写一个处理程序(handler)来返回所有项目
在此之前,我们可以访问gin官网,先下载gin:
go get -u github.com/gin-gonic/gin
package main
import (
"net/http"
"github.com/gin-gonic/gin"
)
// album represents data about a record album.
type album struct {
ID string `json:"id"`
Title string `json:"title"`
Artist string `json:"artist"`
Price float64 `json:"price"`
}
// albums slice to seed record album data.
var albums = []album{
{ID: "1", Title: "Blue Train", Artist: "John Coltrane", Price: 56.99},
{ID: "2", Title: "Jeru", Artist: "Gerry Mulligan", Price: 17.99},
{ID: "3", Title: "Sarah Vaughan and Clifford Brown", Artist: "Sarah Vaughan", Price: 39.99},
}
func main() {
// 使用 gin.Default() 进行 Gin 路由初始化
router := gin.Default()
// 使用GET函数,建立一个关联, /albums 端点路径将使用 getAlbums 处理程序进行请求的处理。
// 请注意,我们传递的是 getAlbums 函数的名称。
// 这与传递函数结果不同,传递函数结果时,您需要传递 getAlbums()(请注意括号)。
router.GET("/albums", getAlbums)
router.GET("/albums/:id", getAlbumByID)
router.POST("/albums", postAlbums)
// 使用 Run 函数将路由注册(附加)到 http.Server 并启动服务器。
router.Run("localhost:8080")
}
// getAlbums responds with the list of all albums as JSON.
// 此函数接收 gin.Context 参数,gin.Context 是Gin框架中至关重要的部分。
// 它包含请求详细信息、验证和序列化 JSON 等。
// (尽管名称相似,但这与 Go 的内置 context 包不同。)
func getAlbums(c *gin.Context) {
// 调用 Context.IndentJSON 可以序列化 albums struct(结构体)为JSON,并添加到响应中。
// 该方法的第一个参数是 HTTP 状态码,用来表示发送至客户端的状态,net/http 包中的 http.StatusOK代表 200 状态码
// 我们也可以使用 Context.JSON 方法替代 Context.IndentJSON,以发送更紧凑的JSON。
// 实际上,缩进形式在调试时更容易使用,并且响应的实际大小差异很小
c.IndentedJSON(http.StatusOK, albums)
}
// postAlbums adds an album from JSON received in the request body.
func postAlbums(c *gin.Context) {
var newAlbum album
// Call BindJSON to bind the received JSON to
// newAlbum.
// 使用Context.BindJSON方法将请求体数据以JSON的形式绑定给 newAlbum
if err := c.BindJSON(&newAlbum); err != nil {
return
}
// Add the new album to the slice.
// 将转化后的序列化JSON 附加到 albums 切片中
albums = append(albums, newAlbum)
// 向客户端响应 201 状态码,并返回 成功附加的数据
c.IndentedJSON(http.StatusCreated, newAlbum)
}
// getAlbumByID locates the album whose ID value matches the id
// parameter sent by the client, then returns that album as a response.
// 通过入参 ID 查询指定 album 并响应到客户端
func getAlbumByID(c *gin.Context) {
// 使用 Context.Param 从 URL 中检索 id 路径参数。
// 因此将此处理程序映射到路径时,要在路径中包含该参数的占位符 :id。
id := c.Param("id")
// Loop through the list of albums, looking for
// an album whose ID value matches the parameter.
// 循环遍历切片中的 albums struct,查找 ID 字段值与 id 参数值匹配的专辑结构。
// 正式的应用中,一般为数据库查询
// 如果找到,则将该 album 结构序列化为 JSON,并将其作为带有 200 OK HTTP 的响应返回。
// 如果找不到匹配的 album,则使用 Context.IndentedJSON 返回 HTTP 404 错误
for _, a := range albums {
if a.ID == id {
c.IndentedJSON(http.StatusOK, a)
return
}
}
c.IndentedJSON(http.StatusNotFound, gin.H{"message": "album not found"})
}
如果想要更规范地编码,可以参考 头部章节:Go编码前置知识 及 Effective Go
接下来,继续进行 Go 中的 泛型(generics)的学习
7. 泛型入门
本节介绍了 Go 中泛型的基础知识。借助泛型,可以声明和使用能与调用代码提供的一组类型中的任何一个一起使用的函数或类型。
此示例是非泛型函数使用示例
package main
import "fmt"
func SumInts(m map[string]int64) int64 {
s := int64(0)
for _, v := range m {
s += v
}
return s
}
func SumFloats(m map[string]float64) float64 {
s := float64(0)
for _, v := range m {
s += v
}
return s
}
func main() {
ints := map[string]int64{
"first": 10,
"second": 12,
}
floats := map[string]float64{
"first": 12.345,
"second": 13.234,
}
fmt.Printf("ints: %v, floats: %v", SumInts(ints), SumFloats(floats))
}
在本节中,我们使用泛型,添加一个通用函数,该函数可以接收包含整数或浮点值的Map,从而有效地用一个函数替换刚刚编写的两个函数。
package main
import "fmt"
// func SumInts(m map[string]int64) int64 {
// s := int64(0)
// for _, v := range m {
// s += v
// }
// return s
// }
// func SumFloats(m map[string]float64) float64 {
// s := float64(0)
// for _, v := range m {
// s += v
// }
// return s
// }
// SumIntsOrFloats sums the values of map m. It supports both int64 and float64
// as types for map values.
// 其中[]包裹的参数,称为类型参数,括号内的为普通参数,类型参数指定了类型声明,
// K 声明为 comparable, V 声明为 int64 或者 float64
// 在普通参数的类型中,可以使用声明标识 K 和 V 代替 譬如 map[string]int64、mapp[string]float64
func SumIntsOrFloats[K comparable, V int64 | float64](m map[K]V) V {
var s V
for _, v := range m {
s += v
}
return s
}
func main() {
ints := map[string]int64{
"first": 10,
"second": 12,
}
floats := map[string]float64{
"first": 12.345,
"second": 13.234,
}
// fmt.Printf("ints: %v, floats: %v", SumInts(ints), SumFloats(floats))
// 类型参数,在调用时可有可无,Go会自行推断
// fmt.Printf("Generic Sums: %v and %v\n",
// SumIntsOrFloats[string, int64](ints),
// SumIntsOrFloats[string, float64](floats))
fmt.Printf("ints: %v, floats: %v", SumIntsOrFloats(ints), SumIntsOrFloats(floats))
}
最后,我们将使用接口(type XX interface)对本次代码中的可复用类型进行约束:
package main
import "fmt"
// 通过 type 声明了 Number 类型的约束,此约束,可以代替 int64 | float64 的组合
type Number interface {
int64 | float64
}
// func SumInts(m map[string]int64) int64 {
// s := int64(0)
// for _, v := range m {
// s += v
// }
// return s
// }
// func SumFloats(m map[string]float64) float64 {
// s := float64(0)
// for _, v := range m {
// s += v
// }
// return s
// }
// SumIntsOrFloats sums the values of map m. It supports both int64 and float64
// as types for map values.
// 其中[]包裹的参数,称为类型参数,括号内的为普通参数,类型参数指定了类型声明,
// K 声明为 comparable, V 声明为 int64 或者 float64
// 在普通参数的类型中,可以使用声明标识 K 和 V 代替 譬如 map[string]int64、mapp[string]float64
// func SumIntsOrFloats[K comparable, V int64 | float64](m map[K]V) V {
// var s V
// for _, v := range m {
// s += v
// }
// return s
// }
func SumIntsOrFloats[K comparable, V Number](m map[K]V) V {
var s V
for _, v := range m {
s += v
}
return s
}
func main() {
ints := map[string]int64{
"first": 10,
"second": 12,
}
floats := map[string]float64{
"first": 12.345,
"second": 13.234,
}
// fmt.Printf("ints: %v, floats: %v", SumInts(ints), SumFloats(floats))
fmt.Printf("ints: %v, floats: %v", SumIntsOrFloats(ints), SumIntsOrFloats(floats))
}
完成以上知识,我们已经掌握了Go的基本编码模式,接下来,拓展介绍下模糊测试的入门知识。
8. 模糊测试入门
接下来,我们通过一个案例,进行模糊测试:
在我们的workspace中,创建一个文件夹,名为 fuzz,文件夹内新建文件 main.go,并键入如�下代码:
package main
import "fmt"
func Reverse(s string) string {
b := []byte(s)
for i, j := 0, len(b)-1; i < len(b)/2; i, j = i+1, j-1 {
b[i], b[j] = b[j], b[i]
}
return string(b)
}
func main() {
input := "The quick brown fox jumped over the lazy dog"
rev := Reverse(input)
doubleRev := Reverse(rev)
fmt.Printf("original: %q\n", input)
fmt.Printf("reversed: %q\n", rev)
fmt.Printf("reversed again: %q\n", doubleRev)
}
以上代码,实现了字符串的反转功能,我们运行后,可以看到预期效果,但是作为健壮的包使用, 我们还需要添加测试进行验证,之前我们使用了单元测试,提供确定的输入,和期望的输出,进行预期验证。 单元测试有局限性,即每个输入都必须由开发人员添加到测试中。模糊测试的一个好处是,它会为您的代码提供输入, 并可能识别您提出的测试用例未达到的极端情况。
接下来,我们添加这两种测试的实现;
- 同级目录新建文件
Reverse_test.go,键入以下代码:
package main
import (
"testing"
"unicode/utf8"
)
// 单元测试
func TestReverse(t *testing.T) {
testcases := []struct {
in, want string
}{
{"Hello, world", "dlrow ,olleH"},
{" ", " "},
{"!12345", "54321!"},
}
for _, tc := range testcases {
rev := Reverse(tc.in)
if rev != tc.want {
t.Errorf("Reverse: %q, want %q", rev, tc.want)
}
}
}
// 模糊测试
func FuzzReverse(f *testing.F) {
testcases := []string{"Hello, world", " ", "!12345"}
for _, tc := range testcases {
f.Add(tc) // Use f.Add to provide a seed corpus
}
f.Fuzz(func(t *testing.T, orig string) {
rev := Reverse(orig)
doubleRev := Reverse(rev)
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", orig, doubleRev)
}
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
}
})
}
模糊测试也有一些局限性。在单元测试中,您可以预测函数的预期输出,并验证实际输出是否符合这些预期。
在进行模糊测试时,您无法预测预期的输出,因为您无法控制输入。
但是,您可以在模糊测试中验证该函数的一些属性。此模糊测试中检查的两个属性是:
- 反转字符串两次可保留原始值
- 反转的字符串保留其作为有效 UTF-8 的状态。
注意单元测试和模糊测试之间的语法差异:
- 函数以 FuzzXxx 而不是 TestXxx 开头,并且testing.F 采用testing.T
- 在您期望看到t.Run执行的地方,您看到的是f.Fuzz 它接受一个模糊测试目标函数, 该函数的参数为*testing.T 以及要模糊测试的类型。单元测试的输入使用f.Add为种子语料库提供输入。
接下来,我们执行 go test 进行测试结果查看,如果该文件中还有其他测试函数,但只想运行模糊测试,
可以运行go test -run=FuzzReverse,进行指定执行。此时,依然是PASS的,因为我们给定了种子语料库的输入预设。
为了提供更全面的模糊测试,一般不指定预设,运行go test -fuzz=Fuzz,让种子语料库使用Fuzz提供的seeds�进行测试,
此时结果出现了失败的情况。
go test -fuzz=Fuzz
# fuzz: elapsed: 0s, gathering baseline coverage: 0/11 completed
# failure while testing seed corpus entry: FuzzReverse/61be1eac0c5fb143
# fuzz: elapsed: 0s, gathering baseline coverage: 3/11 completed
# --- FAIL: FuzzReverse (0.16s)
# --- FAIL: FuzzReverse (0.00s)
# reverse_test.go:36: Reverse produced invalid UTF-8 string "\x90\xdf"
# FAIL
# exit status 1
# FAIL github.com/coderofrat/fuzz 0.975s
出现失败后,会在testdata/fuzz/FuzzReverse目录生成失败日志,内容如下:
go test fuzz v1
string("ߐ") // invalid UTF-8 string "\x90\xdf"
意思是,"ߐ"测试seek按字节反转后,没有通过utf8.ValidString(orig) && !utf8.ValidString(rev)的校验,
因此我们针对这种问题,要进行相应的排错,要检查为什么输入(在本例中为“ߐ”)在反转时导致 Reverse 产生无效字符串,
我们可以检查反转字符串中的runes数量,在过程中是否一致。
接下来,我们改写模糊测试的target函数:
f.Fuzz(func(t *testing.T, orig string) {
rev := Reverse(orig)
doubleRev := Reverse(rev)
// 如果发生错误或者使用 -v 执行测试,此 t.Logf 行将打印到命令行,这可以帮助您调试此特定问题
t.Logf("Number of runes: orig=%d, rev=%d, doubleRev=%d", utf8.RuneCountInString(orig), utf8.RuneCountInString(rev), utf8.RuneCountInString(doubleRev))
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", orig, doubleRev)
}
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
}
})
随后执行go test,再次查看结果:
go test
# --- FAIL: FuzzReverse (0.00s)
# --- FAIL: FuzzReverse/61be1eac0c5fb143 (0.00s)
# reverse_test.go:42: Number of runes: orig=1, rev=2, doubleRev=1
# reverse_test.go:47: Reverse produced invalid UTF-8 string "\x90\xdf"
# FAIL
# exit status 1
# FAIL github.com/coderofrat/fuzz 0.856s
由结果可见,反转过程runes长度有变化。整个种子语料库使用的字符串每个字符都是一个字节。 但是,诸如“泃”、“ߐ”之类的字符可能需要多个字节。因此,逐字节反转字符串将使多字节字符无效。
如果您对 Go 如何处理字符串感到好奇,请阅读博客文章 Go 中的字符串、字节、符文和字符 以获得更深入的了解。
接下来,为了更好地理解这个bug,我们实践改正它:
func Reverse(s string) string {
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r)
}
完整代码:
package main
import "fmt"
// func Reverse(s string) string {
// b := []byte(s)
// for i, j := 0, len(b)-1; i < len(b)/2; i, j = i+1, j-1 {
// b[i], b[j] = b[j], b[i]
// }
// return string(b)
// }
func Reverse(s string) string {
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r)
}
func main() {
input := "The quick brown fox jumped over the lazy dog"
rev := Reverse(input)
doubleRev := Reverse(rev)
fmt.Printf("original: %q\n", input)
fmt.Printf("reversed: %q\n", rev)
fmt.Printf("reversed again: %q\n", doubleRev)
}
主要区别在于 Reverse 现在是迭代字符串中的每个符文(rune),而不是每个字节(byte)。请注意,这只是一个示例,并不能正确处理 组合字符 。
最后,再次执行go test,输出如下:
go test
# PASS
# ok github.com/coderofrat/fuzz 0.945s
这次,错误不再出现,但是为了更加严谨,我们再次使用 -fuzz=Fuzz 参数进行测试:
go test -fuzz=Fuzz
# fuzz: elapsed: 0s, gathering baseline coverage: 0/11 completed
# fuzz: minimizing 32-byte failing input file
# fuzz: elapsed: 1s, gathering baseline coverage: 4/11 completed
# --- FAIL: FuzzReverse (0.74s)
# --- FAIL: FuzzReverse (0.00s)
# reverse_test.go:42: Number of runes: orig=1, rev=1, doubleRev=1
# reverse_test.go:44: Before: "\xd8", after: "�"
# Failing input written to testdata\fuzz\FuzzReverse\5f644fdcef1c73a8
# To re-run:
# go test -run=FuzzReverse/5f644fdcef1c73a8
# FAIL
# exit status 1
# FAIL github.com/coderofrat/fuzz 0.897s
我们可以看到,经过两次反转后,字符串与原始字符串不同。这次输入本身是无效的 unicode。如果我们使用字符串进行模糊测试,这怎么可能呢?
通过�之前的了解,我们可以使用不同的方法进行调试,此时的情况,我们使用debugger解决,较为方便。
仔细查看之前log中的反转后的字符串,发现Before: "\xd8", after: "�"这个错误提示。在 Go 中,字符串是只读的字节切片([]byte),
可以包含无效 UTF-8 的字节。原始字符串是包含一个字节“\x91”的字节切片。当输入字符串设置为 []rune 时,Go 将字节切片编码为 UTF-8,
并用 UTF-8 字符 � 替换该字节。当我们将替换的 UTF-8 字符与输入字节切片进行比较时,它们显然不相等。
我们将在 Reverse 函数中记录有用的调试信息。
func Reverse(s string) string {
fmt.Printf("input: %q\n", s)
r := []rune(s)
fmt.Printf("runes: %q\n", r)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r)
}
这次,我们只想运行失败的测试来检查日志。为此,我们将使用 go test -run,要运行 FuzzXxx/testdata 中的特定语料库条目,您可以为 -run 提供 {FuzzTestName}/{filename}。这在调试时很有用。在这种情况下,将 -run 标志设置为失败测试的精确哈希值:
go test -run=FuzzReverse/5f644fdcef1c73a8
# input: "\xd8"
# runes: ['�']
# input: "�"
# runes: ['�']
# --- FAIL: FuzzReverse (0.00s)
# --- FAIL: FuzzReverse/5f644fdcef1c73a8 (0.00s)
# reverse_test.go:42: Number of runes: orig=1, rev=1, doubleRev=1
# reverse_test.go:44: Before: "\xd8", after: "�"
# FAIL
# exit status 1
# FAIL github.com/coderofrat/fuzz 0.953s
由此可见,输入是无效的unicode,为了修复此问题,如果 Reverse 的输入不是有效的 UTF-8,我们将返回错误。
修复代码如下:
package main
import (
"errors"
"fmt"
"unicode/utf8"
)
// func Reverse(s string) string {
// b := []byte(s)
// for i, j := 0, len(b)-1; i < len(b)/2; i, j = i+1, j-1 {
// b[i], b[j] = b[j], b[i]
// }
// return string(b)
// }
func Reverse(s string) (string, error) {
if !utf8.ValidString(s) {
return s, errors.New("input is not valid UTF-8")
}
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r), nil
}
// func main() {
// input := "The quick brown fox jumped over the lazy dog"
// rev := Reverse(input)
// doubleRev := Reverse(rev)
// fmt.Printf("original: %q\n", input)
// fmt.Printf("reversed: %q\n", rev)
// fmt.Printf("reversed again: %q\n", doubleRev)
// }
// 添加错误情况接收及展示
func main() {
input := "The quick brown fox jumped over the lazy dog"
rev, revErr := Reverse(input)
doubleRev, doubleRevErr := Reverse(rev)
fmt.Printf("original: %q\n", input)
fmt.Printf("reversed: %q, err: %v\n", rev, revErr)
fmt.Printf("reversed again: %q, err: %v\n", doubleRev, doubleRevErr)
}
同时修改模糊测试文件reverse_test.go:
package main
import (
"testing"
"unicode/utf8"
)
func TestReverse(t *testing.T) {
testcases := []struct {
in, want string
}{
{"Hello, world", "dlrow ,olleH"},
{" ", " "},
{"!12345", "54321!"},
}
for _, tc := range testcases {
rev, err := Reverse(tc.in)
// 除了返回之外,您还可以调用 t.Skip() 来停止该模糊输入的执行。
if err != nil {
return
}
if rev != tc.want {
t.Errorf("Reverse: %q, want %q", rev, tc.want)
}
}
}
func FuzzReverse(f *testing.F) {
testcases := []string{"Hello, world", " ", "!12345"}
for _, tc := range testcases {
f.Add(tc) // Use f.Add to provide a seed corpus
}
// f.Fuzz(func(t *testing.T, orig string) {
// rev := Reverse(orig)
// doubleRev := Reverse(rev)
// if orig != doubleRev {
// t.Errorf("Before: %q, after: %q", orig, doubleRev)
// }
// if utf8.ValidString(orig) && !utf8.ValidString(rev) {
// t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
// }
// })
// f.Fuzz(func(t *testing.T, orig string) {
// rev := Reverse(orig)
// doubleRev := Reverse(rev)
// t.Logf("Number of runes: orig=%d, rev=%d, doubleRev=%d", utf8.RuneCountInString(orig), utf8.RuneCountInString(rev), utf8.RuneCountInString(doubleRev))
// if orig != doubleRev {
// t.Errorf("Before: %q, after: %q", orig, doubleRev)
// }
// if utf8.ValidString(orig) && !utf8.ValidString(rev) {
// t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
// }
// })
f.Fuzz(func(t *testing.T, orig string) {
rev, err1 := Reverse(orig)
// 除了返回之外,您还可以调用 t.Skip() 来停止该模糊输入的执行。
if err1 != nil {
return
}
doubleRev, err2 := Reverse(rev)
// 模糊测试针对错误处理情况,直接return即可
if err2 != nil {
return
}
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", orig, doubleRev)
}
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
}
})
}
随后,再次执行:
go test -run=FuzzReverse/5f644fdcef1c73a8
# PASS
# ok github.com/coderofrat/fuzz 0.903s
go test
# PASS
# ok github.com/coderofrat/fuzz 0.071s
使用 go test -fuzz=Fuzz 进行模糊测试,然后过几秒钟后,使用 ctrl-C 停止模糊测试。 除非您传递 -fuzztime 标志,否则模糊测试将一直运行,直到遇到失败的输入。默认如果没有发生故障则永远运行, 可以使用 ctrl-C 中断该过程。
-fuzztime,他限制了模糊测试的执行持续时间( -fuzztime 10s )。
go test -fuzz=Fuzz
# fuzz: elapsed: 0s, gathering baseline coverage: 0/12 completed
# fuzz: elapsed: 0s, gathering baseline coverage: 12/12 completed, now fuzzing with 16 workers
# fuzz: elapsed: 3s, execs: 259354 (86318/sec), new interesting: 31 (total: 43)
# fuzz: elapsed: 6s, execs: 918212 (219941/sec), new interesting: 33 (total: 45)
# fuzz: elapsed: 9s, execs: 1384988 (155418/sec), new interesting: 35 (total: 47)
# fuzz: elapsed: 12s, execs: 1870316 (161724/sec), new interesting: 36 (total: 48)
# fuzz: elapsed: 15s, execs: 2373554 (167990/sec), new interesting: 36 (total: 48)
# fuzz: elapsed: 18s, execs: 3538280 (388194/sec), new interesting: 36 (total: 48)
# fuzz: elapsed: 21s, execs: 4176266 (212605/sec), new interesting: 36 (total: 48)
# fuzz: elapsed: 24s, execs: 5461494 (428533/sec), new interesting: 37 (total: 49)
# fuzz: elapsed: 27s, execs: 6515307 (351303/sec), new interesting: 37 (total: 49)
# fuzz: elapsed: 30s, execs: 7482390 (322079/sec), new interesting: 37 (total: 49)
# fuzz: elapsed: 33s, execs: 8481288 (333279/sec), new interesting: 37 (total: 49)
# fuzz: elapsed: 35s, execs: 9250002 (318175/sec), new interesting: 37 (total: 49)
Ctrl+C
# PASS
# ok github.com/coderofrat/fuzz 36.236s
go test -fuzz=Fuzz -fuzztime=31s
# fuzz: elapsed: 0s, gathering baseline coverage: 0/49 completed
# fuzz: elapsed: 0s, gathering baseline coverage: 49/49 completed, now fuzzing with 16 workers
# fuzz: elapsed: 3s, execs: 1084158 (360639/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 6s, execs: 2175019 (364273/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 9s, execs: 3197978 (341022/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 12s, execs: 4219255 (340351/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 15s, execs: 5239889 (340280/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 18s, execs: 6259160 (339761/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 21s, execs: 7242820 (326784/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 24s, execs: 8241131 (333902/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 27s, execs: 9270668 (343065/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 30s, execs: 10292174 (340619/sec), new interesting: 4 (total: 53)
# fuzz: elapsed: 31s, execs: 10631411 (291237/sec), new interesting: 4 (total: 53)
# PASS
# ok github.com/coderofrat/fuzz 31.263s
除了 -fuzz 标志之外,go test 还添加了几个新标志,可以在文档中查看。
恭喜,我们已经具备开展模糊测试的基础能力啦,接下来,我们要学会使用 govulncheck 查找并修复易受攻击的依赖项。
9. 使用 govulncheck 查找并修复易受攻击的依赖项
本节附原文档地址Find and fix vulnerable dependencies with govulncheck
简述如下: Govulncheck 是一款低噪音工具,可帮助您查找和修复 Go 项目中的易受攻击的依赖项。 它通过扫描项目的依赖项以查找已知漏洞,然后识别代码中对这些漏洞的任何直接或间接调用来实现此目的。
# 在项目文件夹,下载由已知漏洞的依赖版本:
go get golang.org/x/text@v0.3.5
# 下载govulncheck最新版
go install golang.org/x/vuln/cmd/govulncheck@latest
# 执行检查
govulncheck . #含有go.mod的目录
# No vulnerabilities found. 代表没有发现漏洞
至此,我们完成了所有Go基础文档的学习。接下里,通过Go 的交互式学习了解Go的:基本语法和数据结构、方法和接口、以及 Go 的并发(concurrency)原语。
完结时间:20250326
- 20250329 完成 tour of Go,部分习题还无能力实现。😒
- 20250401 思考使用什么 WebDev Framework MVC的,还是接近原生层面的?
- 20250402 补充阅读
Effective Go